

Subtitle: About data quality and Duplicate Management in Power Platform.
The greatness of your toolbox becomes insignificant if you do not take care of your data. It does not matter how great your tools for app creation, automation and presenting data are if you have poor data quality. The outcome of your work will probably not help the end users to better identify the best prospects and target the correct customers. It will definitely not help them to become more efficient in their work, if they have to hack a path through the jungle each morning before they can get to work.
It all comes down to data quality, which does not magically handle itself. However, there are tools within the Power Platform to help you along the way and there are services and solutions which can help you improve and maintain data quality over time.
The Power Platform tools and possibilities
First up is Alternate Keys. When planning for integrations there are cases when you do not want to work with the GUIDs rendered for the rows, instead you might want to use alternate keys, which is a way to get unique values. Yes, that’s correct, you’ll get unique values. So alternate keys can be one step in the right direction depending on your needs. If you want to use this trick to ensure unique values, but you imagine inactive rows being an issue, there’s a tip for you here: Tip #1414: Enforce unique email but ignore inactive records.
In many cases GUIDs are ok and you do not need Alternate Keys. You will not get a totally secure method for avoiding duplicates for a certain table with the tools for Duplicate Management, but you will prevent some duplicates from happening. It is nothing new really, these concepts have been in the platform for a long time, it comes from the good old MSCRM days. Some parts have been improved since then though.
The main concepts for Dataverse Duplicate Management are Duplicate Detection, Duplicate Detection Rules, Duplicate Detection Jobs and Merge functionality. Duplicate detection can be turned on and off for a whole Organization. You can set up different duplicate detection rules and when duplicates are detected there is functionality for merging rows. The merge functionality is available for Leads, Contacts and Accounts. If you need it for some other table, you will need to create a solution of your own.
The duplicate management features in the platform will not stop users completely from adding duplicate data, but if a user tries to create a new row and you have a Duplicate Detection Rule and the new row is a duplicate according to your rule, then the user will get notified and have the freedom with responsibility to choose if the new row should be created or not and also possibility to do a Merge.
If you want to stop the user completely from adding a duplicate in a certain case (without utilizing alternate keys) or if your definition of a duplicate is kind of complicated (span over several tables e.g.), then you have the possibility to create a plugin (use code) and add some business logic which checks the existing rows and if there is such a row which in that specific case is classified as a duplicate, the plugin can prevent the row from being saved and tell the user that he/she is not allowed to create that kind of row.
We will now look at the duplicate management functionality from the perspective “Initial need to regular maintenance”.
Duplicate Detection Settings
You will find the settings in Power Platform Admin Center. Navigate to your environment, choose Settings and expand the Data Management section. There you will find three menu items for Duplicate management.

Duplicate Detection can be turned on or off per environment. Go to Duplicate detection settings and there you will be able to turn it on or off and also to choose when duplicates should be detected.
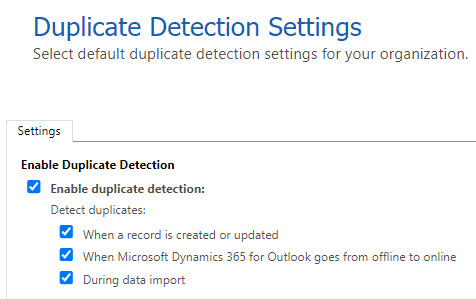
Read more about the settings here: Duplicate detection settings. Let’s look at that time perspective, what it might look like in an initial phase as well as later on.
Step 1 – Jobs to run initially
When you are in the starting phase of getting your organization a new solution for maintaining customer information you might have existing information spread over different places. Some sources might be redundant after your new solution is in place (e.g. Excel files 😉) some might still be relevant (e.g. ERP info). You will need to figure out what data you need to maintain and for how long you should keep that data (GDPR perspective). You also need to figure out how to keep the data up-to-date.
Things to consider here are if there is a proper “source” which we can integrate with, do we need to have the data in Dataverse or just make some of it visible but not actually store it and do we want to use an external service for providing us additional data and help us keeping existing data up to date. Other things to consider are who knows the information best and who should be able to update this information and not. You probably have some kind of ownership for the information. Another thing is how to avoid duplicates. So much fun with planning different parts, but let’s focus on this last part – how to avoid duplicates.
Initially, you want to “clean” your data before it comes info the platform, i.e. before we migrate data or set up an integration. There are services for that but this article will not focus on that part. Now we will look at what we can do when we have the data in Dataverse. There are tools within Power Platform to help you find duplicates.
Initially, you might want one set of rules and run a duplicate detection job and when that has been done, you might want other rules to be applied when the users create new rows.
We will now look at how to run a Duplicate Detection Job.
Let’s pretend that we have had an old system with customer data and we now have that data in Dataverse. Let’s also pretend that we have been using some kind of service from which we get additional data about customers. Let’s say that service includes that we get an ID for each customer and we have not been doing our job managing duplicates so there are duplicates of these IDs. In our new system, we have the possibility to run duplicate detection jobs and that is exactly what we want to do now. We want to check if there are any duplicates for those IDs.
Go to Admin Center, Environment, choose your environment and Settings. Choose Duplicate Detection Jobs under Data Management. You will need to have Duplicate Detection Rules set up before you can run a Duplicate Detection Job. Once you have rules set up, you can follow the wizard and create a job which looks for duplicates. (Do a sneak peak at step 2 if you’re new to those rules).
The Check for Duplicates wizard will help you set up a bulk “job” that finds and cleans up duplicate records. You can then clean the data by deleting, deactivating or merging duplicates which the job has detected. You can also have it scheduled to run daily, which might be handy later on.
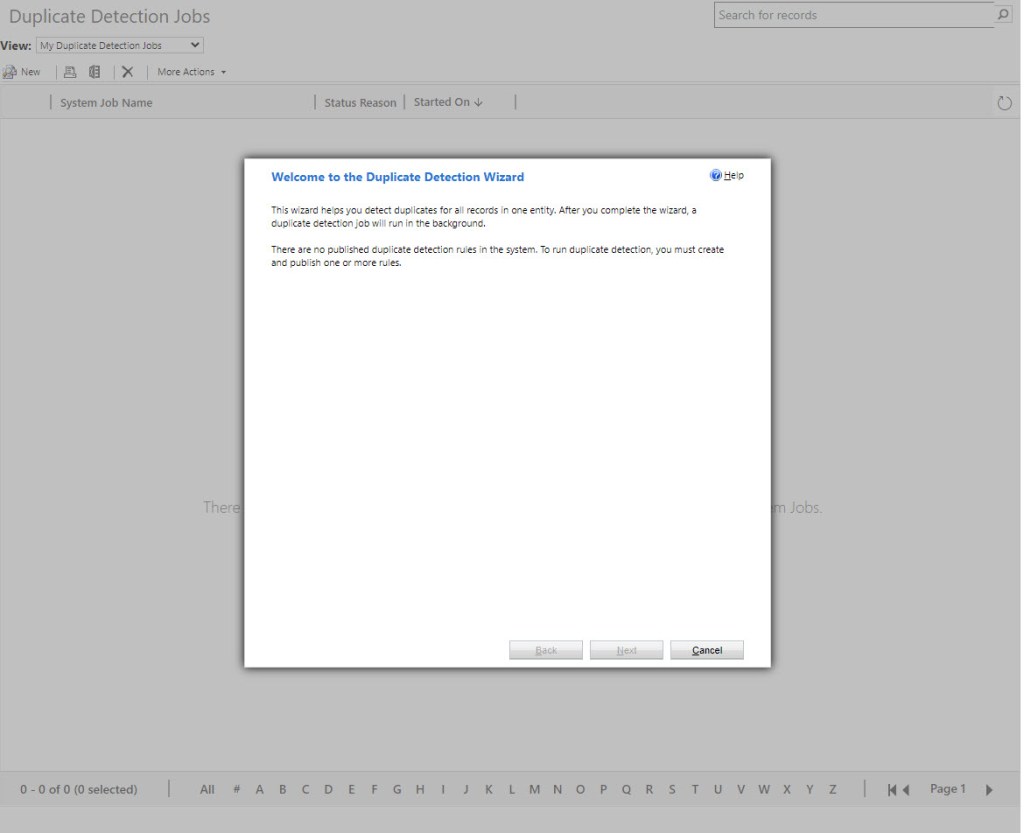
If you have at least one rule published, then you will be able to move forward in the wizard.
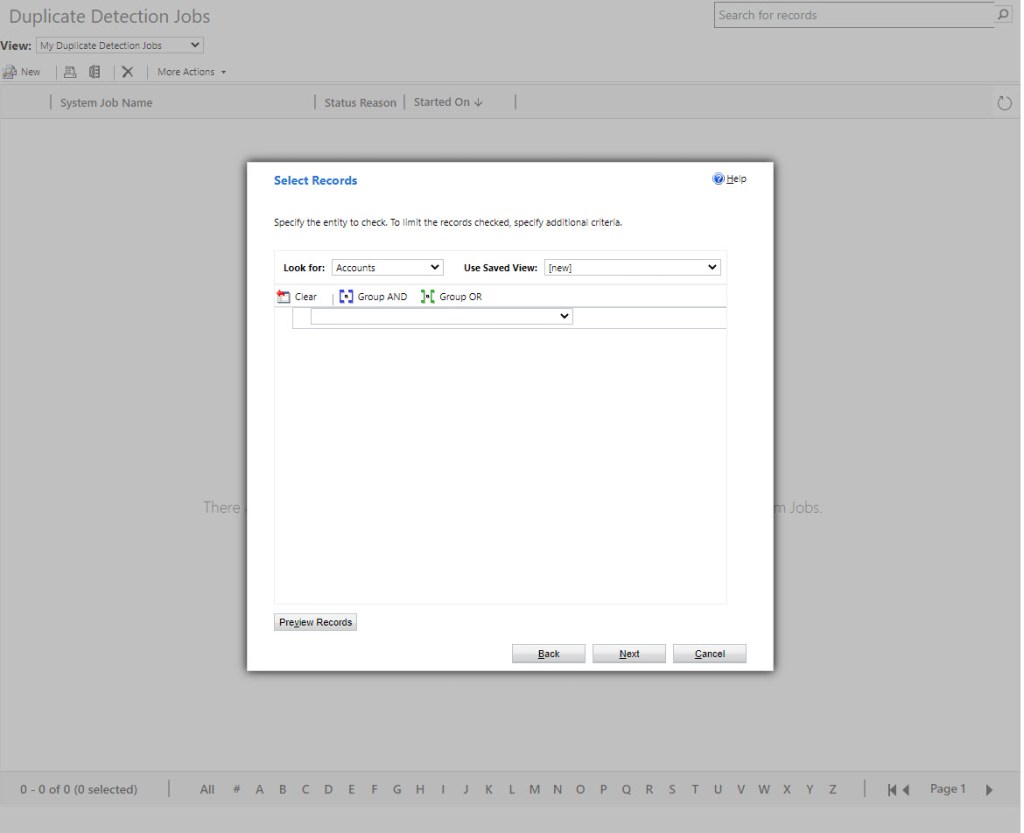
You will then have the possibility to have set this as a scheduled job to be run regularly.
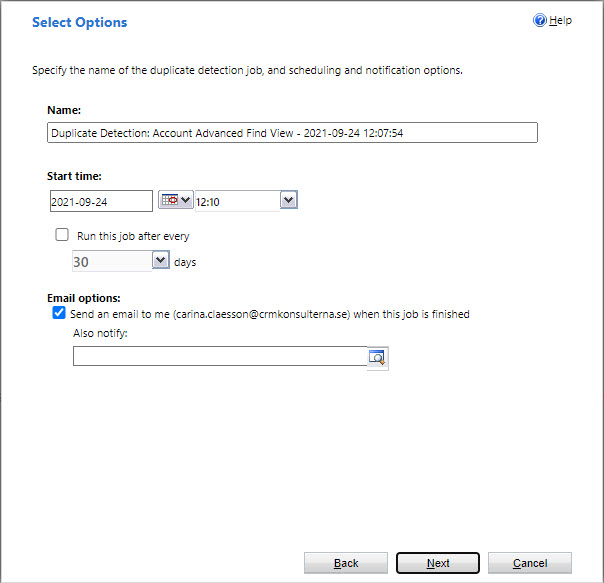
Checking for duplicates with one set of rules and running a job like this might be good in the beginning of a project. But later on you might need other rules. Read omre about setting up jobs here: Duplicate Detection Jobs. Moving on to setting up the rules.
Step 2 – Set up the rules and get help by the platform
So what about making sure users become aware of possible duplicates when adding new rows. In the best of worlds everyone is structured and first make a search for an account before adding a new one. But what if you don’t and there is already such an account that you are about to create. Here the Duplicate Detection Rules comes in. There are some rules defined from scratch and you can also create rules of your own.
The process of setting up rules is well described in MS Docs, read about it here: Duplicate Detection Rules.
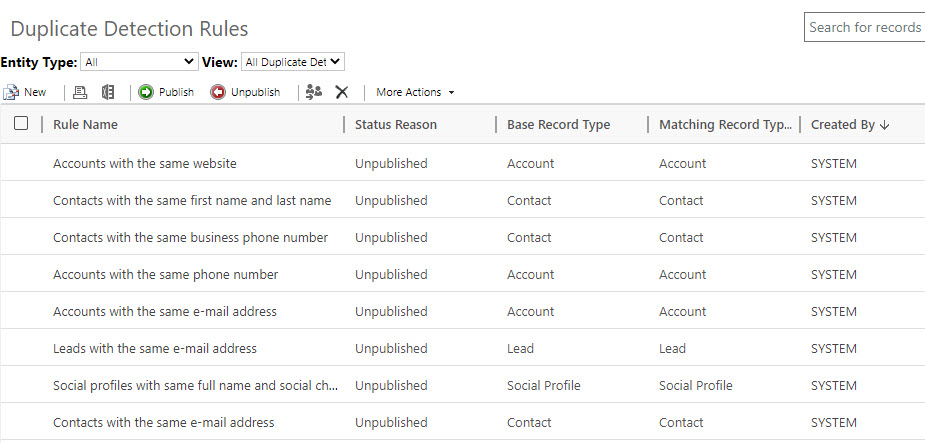
Step 3 – Do something about the clones
When you have found duplicates you will need to take case of that issue. Then you can use the Merge functionality. You can reach the merge functionality e.g. from a view by choosing two rows.
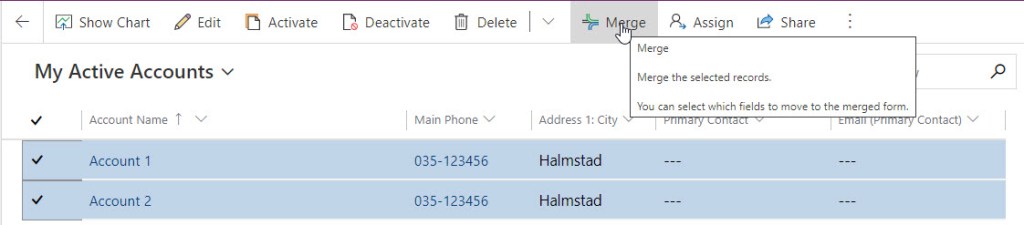
You will then get to choose what information to keep from each row, per section.

Users will also reach the Merge functionality when a Duplicate Detection Rule kicks after the user tries to create a new row of a certain table, for which there is a Duplicate Detection Rule, and the platform detects that the user tries to input what the platform define as a clone. The user then gets a warning about a possible duplicate.
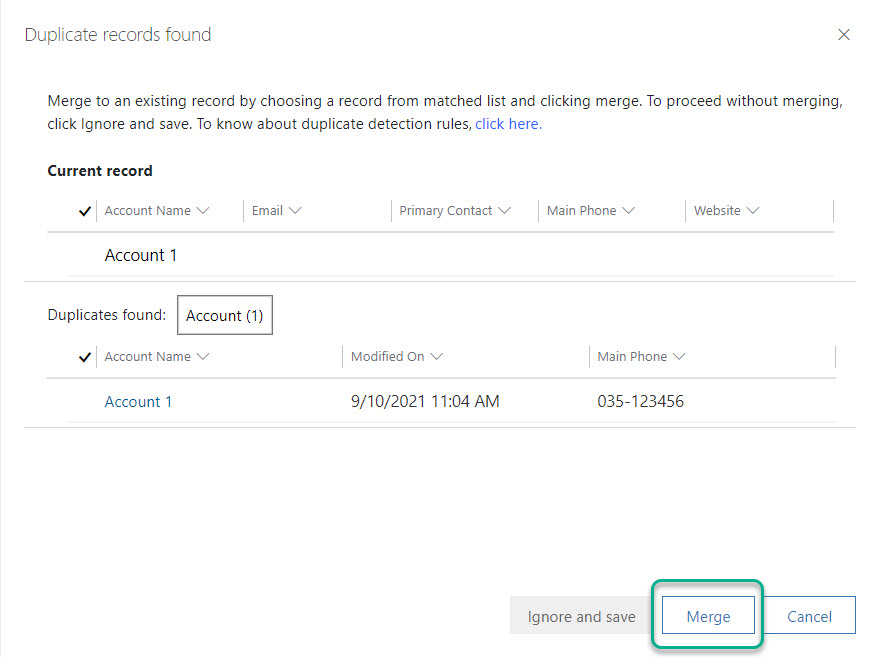
Step 4 – Establish good habits
Regular maintenance simply needs to be done. Example of regular maintenance is to deactivate or remove rows which are no longer relevant. There are many aspects here. We have the GDPR (General Data Protection Regulation), which needs to be thought through and have solutions in place for. Also, you need to make sure the data in your system is still relevant. Some parts can be automated, when you have found certain patterns.
One good habit might be what we do at the office. We have some very structured colleagues who make sure we have some dedicated time for “Registervård” (can be translated to data maintenance), which means to take care of the data in our own CRM and do things like verifying the records where we are owners and make sure the information is still relevant and updated.
Step 5 – Get a low-maintenance landscape
Step 4 was a reminder about the fact that some manual “registervård” is not that bad. In step 5 I will bring up something that might help to reduce the amount of time needed to keep data up-to-date.
There are plants which needs less care than others and if you invest in some of those you are more likely to get a low-maintenance landscape out of your window. In Business Applications there are some investments you can do too. So now you have duplicate detection rules set up, you have informed the users that they should not create duplicates and you have made a routine for yourself to regularly check for duplicates and other weed which can cause a jungle.
The next level might then be to integrate with some service e.g. which can provide you will accurate data about customers, like addresses, turnover, NACE codes etc. and also can give you some additional information about your customers. There are services which spans over different countries. There are third-party tools for this. If you want to know more about it, feel free to reach out to me.
Good to know
- You can have multiple detection rules for the same table, but only have a maximum of five duplicate detection rules published per table at the same time.
- Duplicate detection works with D365 for tablets, but not for D365 for phones.
- Duplicates can’t be detected when a user merges two records, converts a lead, or saves an activity as completed. Same with when a user changes the status of a row, e.g. activating or reactivating it.
- The Merge option is available only for Account, Lead, and Contact entities.
- You should set the duplicate detection criteria on a field that has unique values, e.g. e-mail.
- There are services and third-party solutions for keeping data-up-to date (address info, different company and employment related info etc.)
Conclusions
If you rely on the system only and think that data quality is something that handles itself, you might end up with a jungle. You need to actively work with your data. When you have identified some patterns, then you can automate some parts. Make use of the tools in the platform, work actively with data quality and consider to look at a service for keeping your data up-to-date.
By the way, I do not mind the jungle as long as it is not an unwanted jungle in my garden and as long as it does not live in Dataverse.
Read More in MS Docs
Qualifying Leads and Managing Duplicates
Photo by Claudio Schwarz on Unsplash

2 thoughts on “How to avoid a Dataverse jungle”